Ai文字轉語音、語音轉文字! 這幾種方法你最好要知道
从此存储库的“发布”部分下载 WhisperDesktop.zip,解压缩 ZIP,然后运行 WhisperDesktop.exe。
在第一个屏幕上,它会要求您下载模型。我推荐ggml-medium.bin(大小为 1.42GB),因为我主要使用该模型测试了软件。

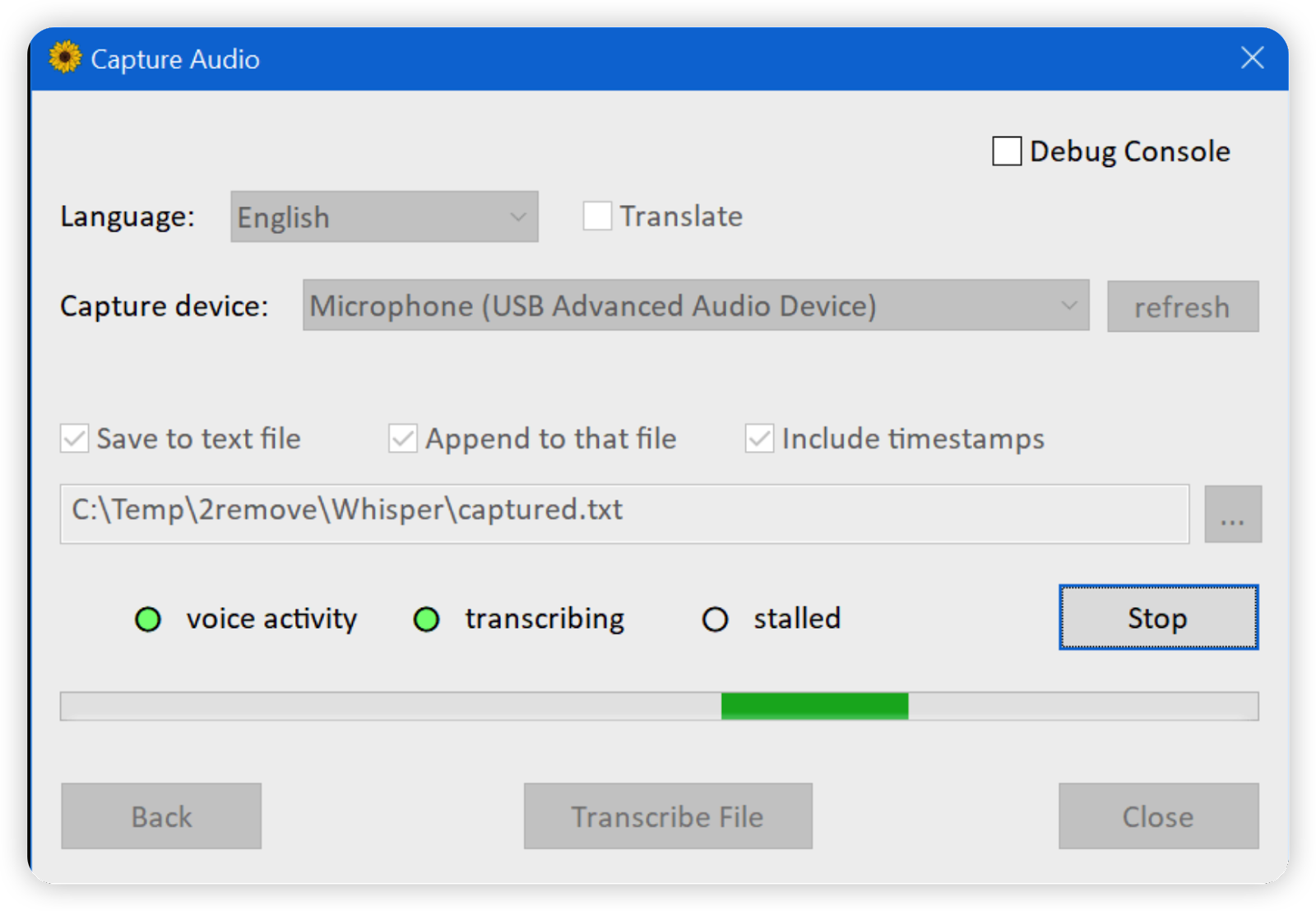
下一个屏幕允许转录音频文件。

还有另一个屏幕允许从麦克风捕获和转录或翻译实时音频
特征
-
基于 DirectCompute 的供应商不可知的 GPGPU;该技术的另一个名称是“Direct3D 11 中的计算着色器”
-
纯 C++ 实现,除了基本的 OS 组件外没有运行时依赖性
-
比 OpenAI 的实现快得多。
在我配备 GeForce 1080Ti GPU 的中型台式计算机上, 使用 PyTorch 和 CUDA 转录3 分 24 秒的演讲需要 45 秒,但使用我的实现和 DirectCompute 只需要 19 秒。
趣闻:这是 9.63 GB 的运行时依赖项,而 431 KB
Whisper.dll -
混合 F16 / F32 精度:自 D3D 版本 10.0 起,Windows 需要缓冲区 的支持
R16_FLOAT -
内置性能分析器,可测量单个计算着色器的执行时间
-
内存使用率低
-
用于音频处理的媒体基础,支持大多数音频和视频格式(Ogg Vorbis 除外),以及大多数在 Windows 上运行的音频捕获设备(除了一些专业的,它们只实现 ASIO API )。
-
用于音频捕获的语音活动检测。
该实现基于Mohammad Moattar 和 Mahdi Homayoonpoor 于2009 年发表的文章 “一种简单但高效的实时语音活动检测算法”。
-
易于使用的 COM 风格 API,nuget 上可用的惯用 C# 包装器
-
提供预构建的二进制文件
唯一受支持的平台是 64 位 Windows。应该可以在 Windows 8.1 或更高版本上运行,但我只在 Windows 10 上测试过。该库需要支持 Direct3D 11.0 的 GPU,这在 2023 年就意味着“任何硬件 GPU”。最新的不支持 D3D 11.0 的 GPU 是 2011 年的 Intel Sandy Bridge。
开发者指南
构建说明
-
克隆这个存储库
-
在 Visual Studio 2022 中打开
WhisperCpp.sln。我使用的是免费软件社区版,版本 17.4.4。 -
切换到
Release配置 -
在解决方案的子文件夹中构建并运行
CompressShadersC# 项目。Tools要运行该项目,请在 visual studio 中右键单击“Set as startup project”,然后在 VS 的主菜单中单击“Debug / Start Without Debugging”。成功完成后,您应该会看到一个控制台窗口,其中包含如下一行:Compressed 46 compute shaders, 123.5 kb -> 18.0 kb -
构建
Whisper项目以获取本机 DLL,或WhisperNet用于 C# 包装器和 nuget 包,或示例。
其他注意事项
.msm如果您要在使用 Visual C++ 2022 或更新版本构建的软件中使用该库,您可能会以合并模块或vc_redist.x64.exe二进制文件的形式重新分发 Visual C++ 运行时 DLL 。如果这样做,请右键单击Whisper项目,属性,C/C++,代码生成,将“运行时库”设置从 切换Multi-threaded (/MT)到Multi-threaded DLL (/MD),然后重建:二进制文件将变小。
该库包括RenderDoc GPU 调试器集成。从 RenderDoc 启动程序时,按住 F12 键以捕获计算调用。如果您要调试 HLSL 着色器,请使用 DLL 的调试版本,它包括着色器的调试版本,您将在调试器中获得更好的用户体验。
该存储库包含许多仅用于开发的代码:耦合替代模型实现、某些计算着色器的兼容 FP64 版本、调试跟踪和比较跟踪的工具等。这些东西被预处理器宏或标志禁用,constexpr我希望留在这里没问题。
性能说明
我在这所房子里选择的 GPU 数量有限。具体来说,我针对 nVidia 1080Ti、Ryzen 7 5700G 内的 Radeon Vega 8 和 Ryzen 5 5600U 内的 Radeon Vega 7 进行了优化。这是摘要。
nVidia 为大型型号提供 5.8 的相对速度,为中型型号提供 10.6。
AMD Ryzen 5 5600U APU 为中型型号提供大约 2.2 的相对速度。不是很好,但仍然比实时快得多。
我还在nVidia 1650上测试过:比 1080Ti 慢但相当好,比实时快得多。我还在 Core i7-3612QM 内部的 Intel HD Graphics 4000 上进行了测试,相对速度为中型型号为 0.14,小型型号为 0.44。这比实时慢得多,但我很高兴地发现我的软件甚至可以在2012 年推出的集成移动 GPU 上运行。
我不确定独立的 AMD GPU 或集成的 Intel GPU 的性能是否理想,没有专门针对它们进行优化。理想情况下,他们可能需要几个最昂贵的计算着色器的构建略有不同,mulMatTiled.hlsl并且mulMatByRowTiled.hlsl可能需要进行其他调整,例如头文件useReshapedMatMul()中的值。Whisper/D3D/device.h
我不知道如何衡量,但我觉得瓶颈是内存,而不是计算。Hacker News 上有人在3060Ti上进行了测试,该版本具有 GDDR6 显存。与 1080Ti 相比,该 GPU 具有 1.3 倍的 FP32 FLOPS,但具有 0.92 倍的 VRAM 带宽。该应用程序在 3060Ti 上慢了大约 10%。
进一步优化
我只花了几天时间优化这些着色器的性能。
有可能做得更好,这里有一些想法。
-
与 FP32 相比,Radeon Vega 或 nVidia 1650 等较新的 GPU 具有更高的 FP16 性能,但我的计算着色器仅使用 FP32 数据类型。
-
在当前版本中,FP16 张量使用着色器资源视图向上转换加载的值,使用无序访问视图向下转换存储的值。切换到字节地址缓冲区、加载/存储完整的 4 字节值以及在 HLSL 中使用/内在函数进行向上转换/向下转换
可能是个好主意。
f16tof32``f32tof16 -
在当前版本中,所有着色器都是离线编译的,并且
Whisper.dll包括 DXBC 字节码。HLSL 编译器
D3DCompiler_47.dll是一个操作系统组件,速度非常快。对于昂贵的计算着色器,交付 HLSL 而不是 DXBC 可能是个好主意,并在启动时使用特定于环境的宏值进行编译。 -
将整个系统从 D3D11 升级到 D3D12 可能是个好主意。
较新的 API 更难使用,但包含 D3D11 未公开的潜在有用功能: wave intrinsics和显式 FP16。
缺少的功能
未实现自动语言检测。
在当前版本中,实时音频捕获的延迟很高。
具体来说,根据语音检测,该数字约为 5-10 秒。
至少在我的测试中,当我提供太短的音频片段时,模型并不满意。
我已经增加了延迟并结束了,但理想情况下,这需要更好的修复以获得最佳用户体验。
最后的话
从我的角度来看,这是一个无偿的业余爱好项目,我在 2022-23 冬季节日期间完成了它。
该代码可能有错误。
该软件“按原样”提供,不提供任何形式的保证。
感谢Georgi Gerganov的whisper.cpp实现,以及 GGML 二进制格式的模型。我不会编程 Python,我对 ML 生态系统一无所知。如果没有一个好的 C++ 参考实现来测试我的版本,我什至不会开始这个项目。
whisper.cpp 项目有一个示例,它使用 相同的 GGML 实现来运行另一个 OpenAI 的模型GPT-2。使用该项目中已经实现的计算着色器和相关基础设施来支持该 ML 模型应该不难。
如果你觉得这有用,如果你考虑向“活着回来”基金会捐款,我将非常感激
1.Whisper :開源項目 【點擊下載】
2.ggml-medium 語音模型: 【點擊下載】
3.CPU版的Whisper:【開源項目】
微软Azure文本转语音网址:
https://azure.microsoft.com/zh-cn/products/cognitive-services/text-to-speech/#features
Azure Speech Download:
https://greasyfork.org/zh-CN/scripts/444347-azure-speech-download需要提前安装浏览器油猴拓展
插件地址:
- 1、Talk-to-ChatGPT插件:
- Talk-to-ChatGPT - Chrome 应用商店 (google.com)
- 2、Speak to ChatGPT插件:
- Speak to ChatGPT - Chrome 应用商店 (google.com)
- 3、Speak to ChatGPT插件:
- https://greasyfork.org/en/scripts/459890-talkgpt


评论
发表评论